Written by: Jeff Mikos
Reading time: 6 minutes
Updated: 04/09/2026
Published: 04/09/2026
A PIM enforces and scales the product data model you design into it. If that model hasn’t been designed yet, for instance if your identifiers are ambiguous, your variant logic is inconsistent or your attribute ownership is unclear then you’re about to amplify every inconsistency you have, at industrial speed.
The organizations that get this right treat the pre-PIM implementation phase as a distinct program of work, not a migration warm-up. They come out of it with seven concrete deliverables before a single record moves:
- a canonical data model
- a taxonomy strategy
- an attribute dictionary
- a system-of-record map
- governance roles
- a readiness scorecard
- a phased migration plan.
Everything else follows from those.
The Garbage-In Problem Is a Governance Problem
The familiar “garbage in, garbage out” principle understates what actually happens. When you centralize for omnichannel publishing, ambiguity in identifiers, variant logic, packaging hierarchies, or attribute definitions becomes a repeatable failure mode across every channel feed, marketplace submission, and internal workflow. The PIM makes the gaps visible. It also makes them expensive.
GS1’s National Data Quality Program is explicit about this: data governance is a business process, not a project. Executive support, standards commitment, consistent processes. Not a one-time cleanse before go-live. This matters because most PIM failures aren’t software failures. They’re process failures that the software made harder to ignore.
The economic case for front-loading this work is real. A Nestlé Professional case study with GS1 describes the recurring operational costs tied to inactive products and missing marketing content. These are data readiness failures that any PIM would have inherited and propagated.
What “Product” Actually Means Across Your Systems
Before you can model product data, you need an honest answer to a question most teams sidestep: what is a product in your organization? In most B2B manufacturers and distributors we work with, the answer is not one thing. It’s at least four.
Product identity entities
A durable product identity key is the anchor for relationships, pricing, and content. In supply chain contexts, GS1’s GTIN serves this role. Even if you don’t use GTINs, the architectural pattern holds: you need one unambiguous identifier per orderable unit before the PIM has any surface to attach data to.
Packaging hierarchy entities
Many categories require a packaging hierarchy (consumer unit, inner pack, case, pallet). Pre-PIM modeling needs to decide whether packaging levels are modeled as separate SKUs, as logistics units linked to a sellable SKU, or both. Inaccurate packaging data causes real operational problems: truck capacity errors, warehouse automation failures.
Variant modeling
Variant modeling is where many PIM implementations fail if pre-work is incomplete. The standard pattern is a parent product (style or model) with variant SKUs (specific combinations of size, color, or configuration). You need to specify which attributes live on the parent versus the SKU, which attributes are the “varies by” dimensions, and how to manage shared assets. Not doing this in advance means redoing the model mid-implementation.
Compliance and regulated attributes
Compliance requirements force new data entities: certificates, safety data sheets, ingredient declarations, warning statements. These also carry auditability expectations most PIMs weren’t natively built to handle. With the EU’s Digital Product Passport requirements expanding under the Ecodesign for Sustainable Products Regulation, this is no longer a future consideration for companies selling into Europe. Pre-PIM design should establish the pattern early: regulated attributes modeled as structured facts with provenance, effective dates, and jurisdiction applicability.
Maturity Before Migration: A Five-Level Framework
Where your data is today determines what you can do tomorrow. We use a five-level model to anchor readiness assessments, drawing from ISO/IEC 25012’s data quality characteristics and GS1’s Data Quality Framework.
| Level | What data looks like | What processes look like | Pre-PIM implication |
| Initial | Scattered across ERP & spreadsheets; inconsistent definitions; low trust | Ad hoc fixes via email; limited audit trail | Do not migrate broadly — start with discovery and canonical modeling |
| Defined | Draft attribute dictionary; partial taxonomy; some validation rules | Item setup documented for core products; some approvals | Safe to prototype PIM model and run a pilot migration |
| Managed | Clear ownership per attribute; category-based required fields; controlled vocabularies | Repeatable workflows; QA gates; change control on key identifiers | Ready for phased rollout by category and channel |
| Measured | Quality metrics tracked (completeness, accuracy, timeliness, uniqueness) | SLA-like expectations for enrichment; exceptions handled systematically | Ready to scale; shift focus to optimization and automation |
| Optimized | Continuous improvement; strong provenance and reuse | Governance embedded; onboarding institutionalized | Ready for automation, personalized content, and DPP-style transparency |
Cleanse for Portability, Not for Cosmetics
Pre-migration cleansing has one real objective: making your product data portable, comparable, and enforceable. That means four core transformations.
Deduplication and identity resolution
Choose your identity keys and match rules first. Where GTINs exist, they’re the natural dedup anchor. Where they don’t, define survivorship rules and maintain crosswalk tables so legacy identifiers remain searchable post-migration.
Normalization and standard code sets
This is where most programs recover value quickly. Currency (ISO 4217), country (ISO 3166), language tags (BCP 47), units (UN/CEFACT Rec 20), and dates (ISO 8601). Standardizing these before migration eliminates an entire class of downstream errors.
Enrichment as a governed supply chain
For each attribute, define an authoritative source, allowed contributors, allowable values, and an approval process. Foundational attributes should not be considered changeable once shared across partners. Build that constraint into your process.
Validation rules and publish-readiness gates
Rules must be category- and channel-specific. Apparel needs size, color, care instructions, and at minimum three images before publish. Industrial parts need operating specs and a datasheet. Food needs nutrition fields in regulated markets. Encode these as workflow gates, not guidelines.
The Three Governance Failures to Prevent Before You Start
Most PIM implementations don’t fail at the technical level. They fail at the governance level, and usually in predictable ways.
Migrating without a stable definition of “product” and “SKU”
Symptoms include duplicate products, variants published as separate unrelated products, and inconsistent grouping across channels. The mitigation is explicit: model variant group semantics with defined “varies by” dimensions per category before a single record moves.
“PIM will fix it later” governance
It won’t. GS1 guidance frames governance as an ongoing business process, not a software feature. The pre-PIM phase should produce a governance charter, RACI, and workflow gates that remain in force after go-live. If those artifacts don’t exist, the governance doesn’t exist.
Ignoring regulatory and evidence requirements until late
EU Digital Product Passport direction and sector rules (UDI for medical devices, nutrition labeling for food, care labeling for apparel) require structured fields plus document evidence and auditability. Build the compliance pattern into the model before migration: structured facts with provenance, effective dates, and jurisdiction applicability.
How Complex Is Your Catalog?
Not every pre-PIM program is the same size. The right scope depends on a combination of catalog and organizational factors. Use the matrix below to self-locate before scoping any engagement.
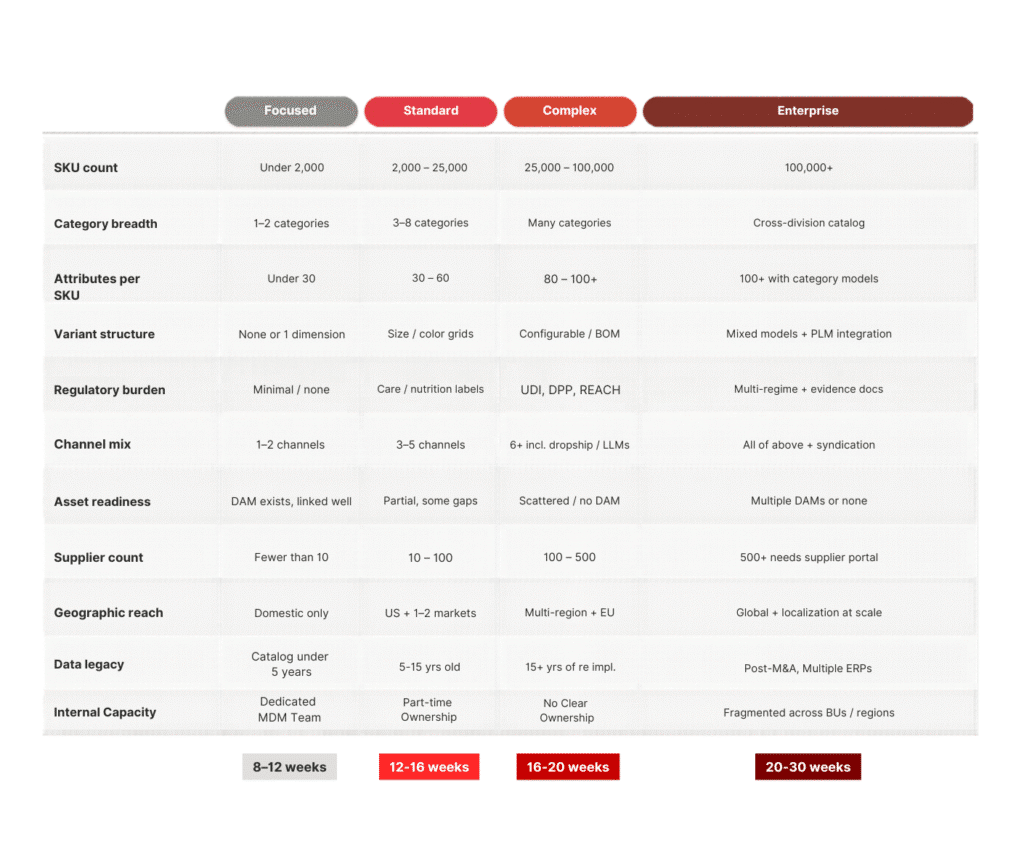
SKU count is the most visible dimension, but it’s rarely the deciding factor on its own. The rows that most reliably move the needle on scope are the ones most prospects underestimate going in.
Data legacy
A 30-year-old industrial catalog that’s never had a governance program has a debt problem. Cleansing and normalization at that age is an excavation, not a cleanup.
Internal capacity
A PIM governance program requires human owners at every attribute group. If those roles don’t exist before the engagement, building them is part of the scope. A company with fragmented ownership across business units or regions needs governance design before data modeling (not after).
Post-M&A data
This is the scenario that most reliably lands clients in Enterprise territory regardless of SKU count. Two acquired product lines mean two data models, two sets of identifiers, two ERP systems, and often two teams with different opinions about what a product is. Reconciling those is a program in itself.
If most of your answers land in one column, that’s your tier. If even one row lands in Enterprise — particularly legacy, capacity, or M&A — budget and timeline as if the whole engagement is Enterprise.
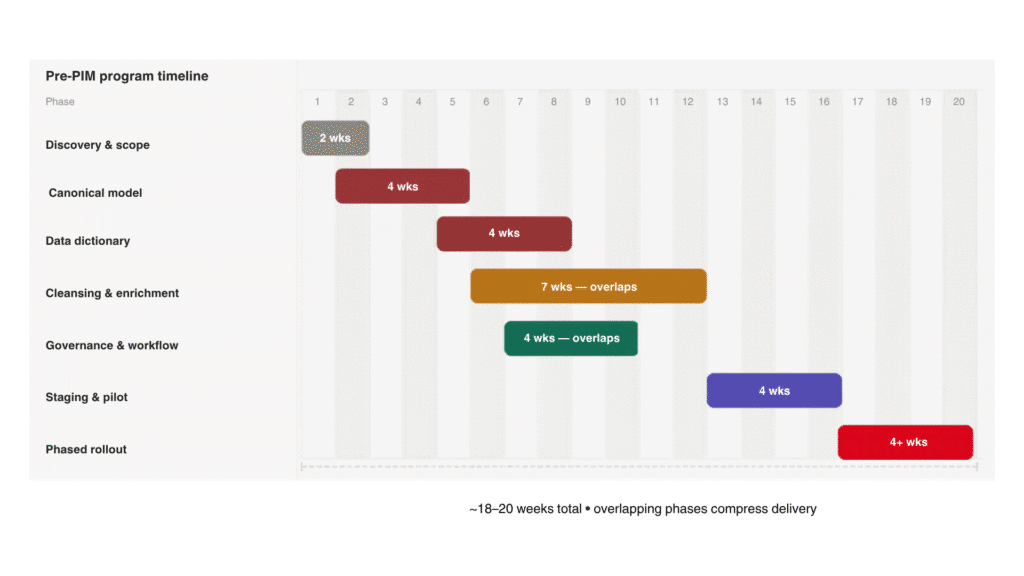
What a Realistic Timeline Looks Like
Pre-PIM is not a two-week sprint. For most organizations with complex catalogs, expect 18 to 20 weeks of structured work before you reach a phased production rollout. The phases overlap in practice, and that overlap is what compresses the timeline — model and governance design must precede tooling scale.
The PIM Is Not the Program
Organizations that treat a PIM selection as the start of their product data program almost always underestimate what they’re building. The software is the enforcer. The operating model — the data model, the taxonomy, the governance, the ownership structure, the workflow gates — that’s the program.
Get that right before you touch the tool, and the implementation almost runs itself. Skip it, and no PIM vendor’s roadmap will save you.
Ready to assess where you stand?
McFadyen’s AI Commerce Readiness Audit evaluates your current commerce stack — including product data infrastructure — and identifies the gaps that matter most before your next platform investment. If you’d prefer to start the conversation directly, we’re happy to share what we’ve seen across similar implementations.
Request an AI Commerce Readiness Audit → https://audit.mcfadyen.ai
Related Articles



Turn Insight Into Impact.
Start Today.
